(译)Contiguous stacks
文章目录
为每一个go协程分配一块连续的栈内存空间,内存在用完的时候会重新分配/复制增长。
为什么?
- 目前的栈拆分机制存在一个”hot spilt”问题– 如果栈空间几乎已满,调用函数则会触发强制分配一个新的栈块。当调用函数返回时,新的栈块将被释放。如果一个调用函数再一个循环中密切调用,alloc/free的开销会导致很大的开销。
- 由于栈拆分没有进行栈块的重新分配与回收,所以当栈块大小超过阈值时,需要一些额外的工作。
对于连续的栈,我们避免了这两个问题。栈块被扩展到所需的大小,从此也不需要做额外的工作 (modulo shrinking, 见下文).。
怎么做?
如何移动堆栈?事实证明,我们编译器的逃逸分析提供了一个非常重要的不确定性:指向栈中数据的指针只会在调用树中传递。任何其他转义(写入全局变量,返回给父对象,写入堆中等)都可以避免在栈上分配数据。这一点确保了指向栈中数据的指针本身也位于栈中。这使得我们在复制栈的情况下易于查找和更新它们。
溢出检查
栈溢出检查与拆分栈的溢出检查非常相似。唯一的区别是,我们不再需要知道参数的大小,因为不再需要将参数复制到新的栈段中。这在某种程度上简化了更多堆栈式例程系列的扩散,并且消除了对大多数NOSPLIT指令的需要。
我们甚至不需要知道栈帧大小。只需要将栈大小加倍,然后重试,如果仍然不合适,我们将再次溢出检查,然后再次将栈大小加倍。重复直到合适为止。
复制
当栈溢出检查触发时:
分配比旧栈大一些的新栈。我们应该以成倍增加的大小进行分配(以限制完成复制的工作次数),并且可能还应向上取舍为一个不错大小的倍数(这样分配更有效)。我目前正在计划使用两种大小的幂,并且将每次重新分配加倍。
将旧栈复制到新栈,栈被视为一个
*byte数组,每个*byte从旧栈复制到新栈。将每个*byte与旧栈的边界进行比较,如果它在范围内,则将其调整为指向新栈中与TOS相同的偏移量。只有真实的指针可以调整,我们需要避免就起来像指针的整数。因此,我们需要一个数据结构来告诉我们,对于堆栈上每个指针的大小,以及它是否是一个指针。幸运的是,Carl正在设计这种数据结构,用于精确GC。
任何从外部进入栈的指针都需要调整。尽管有了逃逸分析,但还有一些遗漏,包括:
> a.延迟调用的函数对象 b.延迟调用的参数 c.延迟调用的函数对象的关闭参数 d.传递给已溢出栈帧的功能对象(在x86中是通过寄存器传递,而不是栈) e.将闭包函数传递给溢出栈帧的函数对象,复制时使用相同的规则–我们需要知道数据是否确实是指针,以及是否指针旧栈。
反射调用处理
Reflect.call调用给定指向参数区域和参数大小的指针的函数。旧的堆栈拆分机制强制使用新的堆栈块,因此可以将可变大小的参数区域分配在堆栈的顶部。新机制需要在堆栈中的任何位置分配这些arg。如果所有栈帧都为固定大小,则实现会更简单,因此要“模拟”可变大小的栈帧,我们定义了一组固定大小为2的幂的栈帧函数,可用作蹦床
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
reflect.call(function, args, argsize)
if argsize <= 16: jump reflect.call16(function, args, argsize)
if argsize <= 32: jump reflect.call32(function, args, argsize)
if argsize <= 64: jump reflect.call64(function, args, argsize)
…
reflect.call16(function, args, argsize)
sp -= 16
copy [args, args+argsize] to [sp, sp+argsize]
call function
copy [sp, sp+argsize] to [args, args+argsize] (for return values)
sp += 16
return |
我建议最大的reflect.call arg大小为64K。
栈复制器需要知道什么是指针,什么不是这些帧。该信息可以通过查看被调用函数的签名来得出。 (对于vararg也调用参数的大小吗?
堆栈跟踪
堆栈跟踪代码在某种程度上简化了,因为它不需要处理堆栈上的拆分
GC
与在堆栈跟踪中一样,简化了G的堆栈的GC遍历。
Defer/panic/recover
这些机制的实现略有变化,并且在大多数情况下得到了简化。旧的机制使用堆栈拆分位置来标记发生恐慌的位置。
Testing
为了进行测试,所有堆栈都将分配到堆外部的某个位置。复制堆栈后,将对旧堆栈进行映射,以便对旧堆栈的任何错误访问都将被捕获。
CGo
待定,我不知道有什么问题。
Shrinking
如果Go例程在其生命周期的开始使用大量堆栈,但是在其生命周期的剩余时间使用较少的堆栈,则大量的堆栈空间将保持空闲状态。我们需要以某种方式恢复该空间。想法:
在GC时,如果go例程使用的堆栈空间不超过X%,则将其复制到较小的堆栈中。如果需要,它将稍后重新生长。
在GC时,如果go例程使用的堆栈空间不超过X%,请将其堆栈保护降低到较小的值。如果下一个GC未能达到目标,则将其复制到较小的堆栈中。
我当前的计划是在GC时,如果go例程最多使用其堆栈的1/4,则释放堆栈底部的½。如果堆栈足够大,我将直接释放它,否则复制。
Starting stacks
默认情况下,所有G均以最小大小的堆栈开始。当G完成时,我们取消分配其堆栈,因为它可能很大,而不是刚好在该G上开始的下一个go例程所要求的(或者也许我们让收缩的代码来处理这个问题?)
我们可以保留一些统计信息,以了解每个go例程使用了多少堆栈(由函数地址指定),并在启动该go例程之前预先分配了多少堆栈。每次执行go例程结束时,都可以更新统计信息。它不是完美的,例如go例程,其堆栈使用取决于数据。但这可能是一个适当的起点。
如果我们愿意在Go例程中记录最大堆栈使用情况,则也可以在拆分堆栈世界中使用此机制。但是,它必须更加保守。在拆分堆栈世界中,分配太大的初始堆栈无法撤消。
Disadvantages
更多虚拟内存压力/碎片。特别是对于大型堆栈,寻找连续的内存来放置堆栈变得更加困难。某些混合方案可能会更好,例如复制到1 MB的大小并在此之后拆分。尽管这可能会有所帮助,但我认为保留这两种机制的额外实现复杂性并不值得。
指向堆栈的指针限制。进入堆栈区域的所有指针都必须严格说明。当前,我们的转义分析确保堆栈中没有杂散指针。将来可能会有一些情况,我们希望允许指针进入堆栈,而此实现将排除它们。我不确定这些情况会怎样,但是这个限制值得一提。
可能需要对运行时C / asm代码进行审核,以确保堆栈指针不会发生任何棘手的情况。
Experiments so far
我正在运行一个原型实现 。它尚未完成,但可以编译简单的示例。
Peano(test / peano.go)修改为最多运行11个!快了10%但是,它对增长率非常敏感,因此请多加一些盐。 (将每个副本的堆栈大小加倍快10%。将每个副本的堆栈增加50%仅快2%。将25%的堆栈增长慢20%。)
“Hot split”测试用例stacksplit.go。与-gcflags -l一起编译以禁用内联。
1 2 3 4 5 6 7 8 9 10 11 12 |
segmented stacks: no split: 1.25925147s with split: 5.372118558s <- triggers hot split problem both split: 1.293200571s contiguous stacks: no split: 1.261624848s with split: 1.262939769s both split: 1.29008309s |
Benchmark examples
我修改了分段堆栈和连续堆栈的实现,以使用环境变量来配置其堆栈段大小/初始堆栈大小。我们可以使用此功能来测试基准测试对堆栈段大小的敏感性。 (对于这些实验,连续的堆栈大小限制为2的幂。)
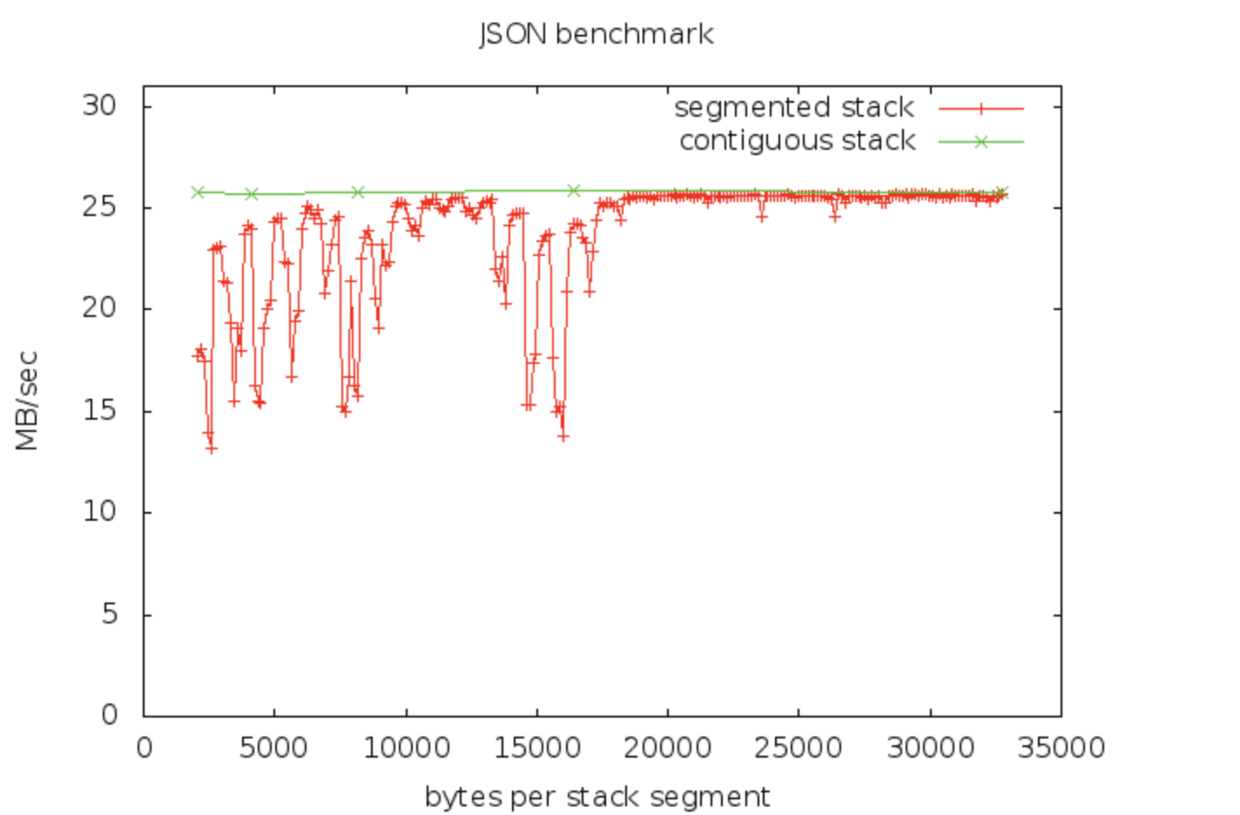
encoding/json/BenchmarkEncode: 历史上一直有人抱怨这一点。See bug 3787.
 )
)
大概最大堆栈使用量为19KB左右,而低于该值时,不良的分割会导致向下的峰值。
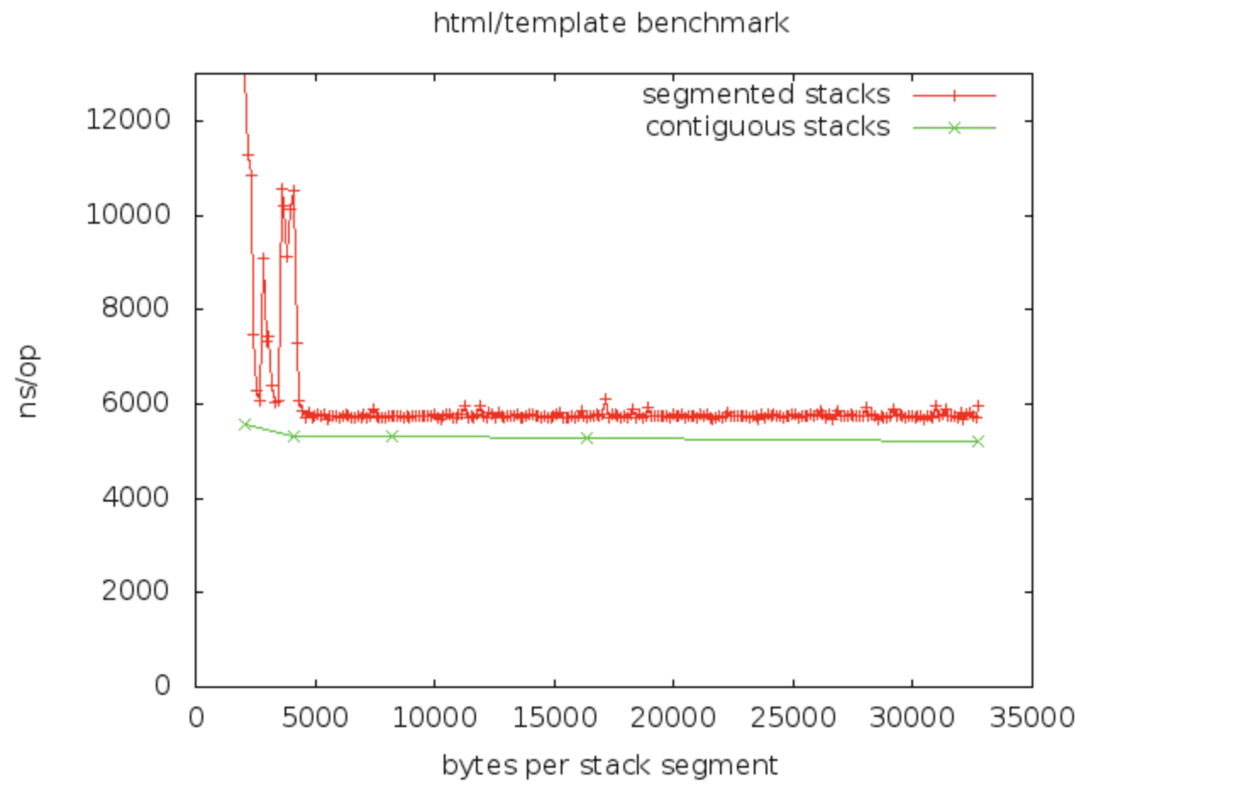
html/template/BenchmarkEscapedExecute: 此基准测试在4096字节/段(默认大小,这是我发现的方式)上存在一个特殊问题。
 )
)
(我不明白为什么连续堆栈隐式渐近更好。)
文章作者 zhengxz
上次更新 2019-11-30