CAP与服务发现组件比较
文章目录
CAP理论概述
一个分布式系统最多只能同时满足一致性(consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
导读
CAP理论概述:分布式系统的CAP理论
一致性模型
一致性指 all nodes see the same data at the same time ,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,所以,一致性,说的就是数据一致性。
一致性又可分为以下3种一致性策略:
1.Linearizability (Strong consistency or Atomic consistency) 强一致性、线性一致性
2.Sequential consistency 顺序一致性
3.Causal consistency 因果一致性
4.Eventual consistency 最后一致性,如果经过一段时间后要求能访问到更新后的数据
CAP中,不可能同时满足的这个一致性指的是强一致性/线性一致性。这里我们主要介绍强一致性跟顺序一致性
线性一致性 (Linearizability)
线性一致性又被称为强一致性或者原子一致性。
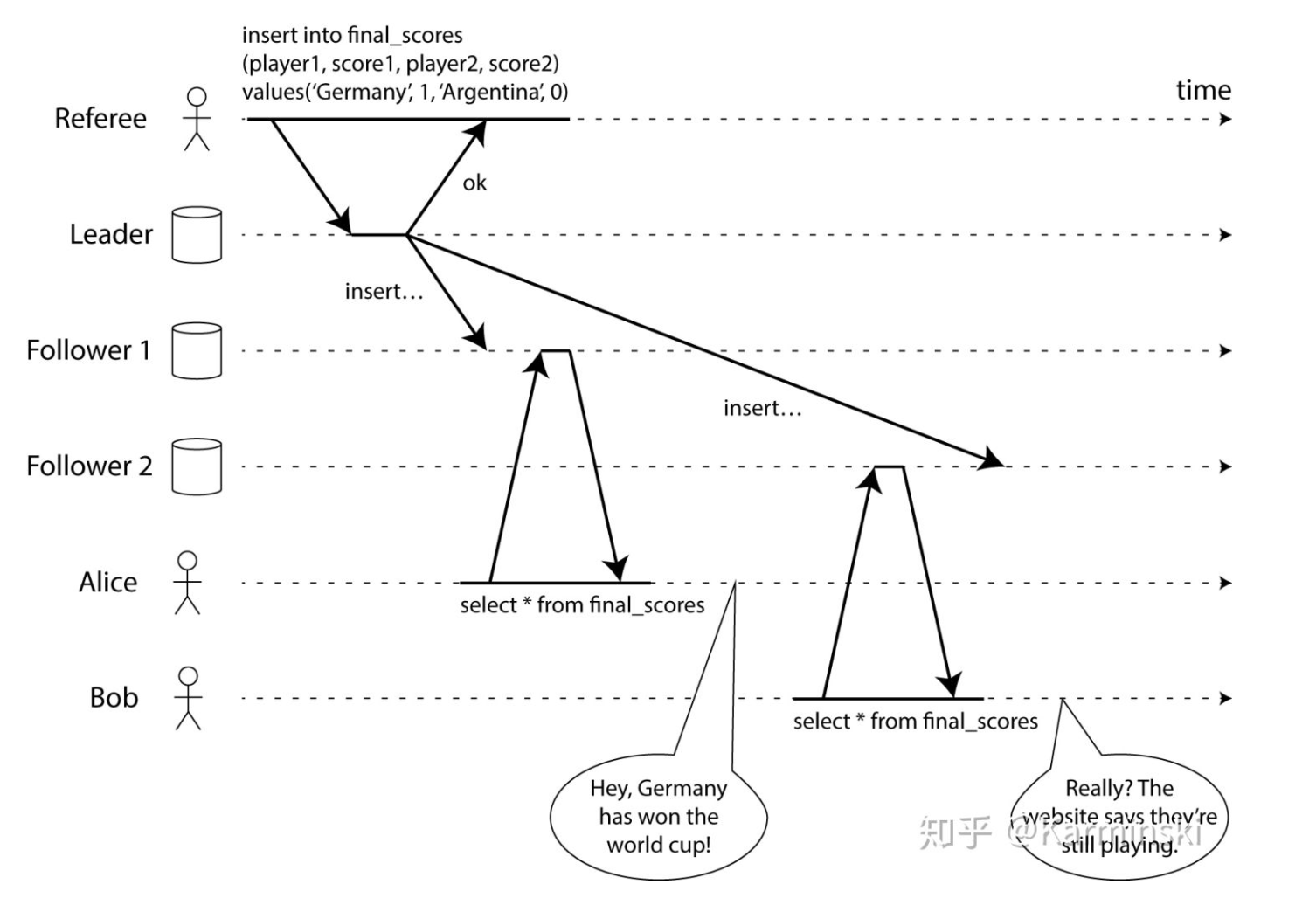
1.Referee:更新比赛的最终结果,先 insert 到数据库 leader 副本,然后 Leader 再复制给两个 Follower 副本
2.Alice:从 Follower 1 中查到了最新的比赛分数
3.Bob:从 Follower 2 中确没查到最新的比赛分数,确显示比赛正在进行
如果 Alice 和 Bob 在同一个房间,各自盯着自己的手机观看比赛,Alice 刷新页面,返现 Germany 赢得比赛,然后告诉 Bob 比赛结果,而 Bob 刷新页面,确显示比赛正在进行,显然这个结果是让人不符合预期的,实际上它也不是符合线性一致性的。对 Bob 来说,他希望看到的结果应该是和 Alice 一样最新的比赛结果,而不是一个旧的结果。
Linearizability的基本的想法是让一个系统看起来好像只有一个数据副本,而且所有的操作都是原子性的。有了这个保证,即使实际中可能有多个副本,应用也不需要担心它们。
Linearizability 要求系统表现的如同一个单一的副本,按照实际的时间顺序来串行的执行线程的读写操作,这也就是『线性』这个定义的由来。然而,满足线性一致性的系统不仅难于实现,更难于提供较高的性能。
·序一致性(Sequential consistency)
Sequential consistency定义实际上对系统提出了两条访问共享对象时的约束:
1.从单个处理器(线程或者进程)的角度上看,其指令的执行顺序以编程中的顺序为准;
2.从所有处理器(线程或者进程)的角度上看,指令的执行保持一个单一的顺序;
约束 1 保证了单个进程的所有指令是按照程序中的顺序来执行;而约束 2 保证了所有的内存操作都是原子的或者说实时地。从编程者的角度,顺序一致性提供了如下图中的抽象。我们可以将共享内存看成一个服务台,而将多个进程看成是接受服务的排队队列:每个进程的内部的读写指令都是按照编程的顺序先来先『服务』,同时服务台在多个队列之间不断切换。
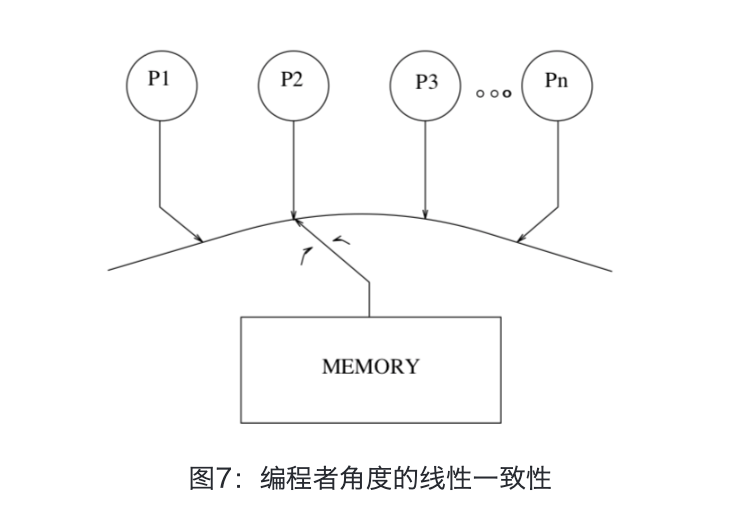
可以看到,相比于 linearizability,Sequential consistency 放松了一致性的要求。首先,其并不要求操作的执行顺序严格按照真实的时间序;其次,其对不同线程之间的读写操作执行先后没有任何要求,只需保证执行是原子性即可。
两者的比较
简单地总结一下两者如下表:
| linearizability | Sequential consistency | |
|---|---|---|
| 单一进程要求按照时间序 | 单一进程内要求按照编程序 | |
| 不同进程要求按照时间序 | 不同进程读写顺序无要求 | |
| 可以通过主动备份实现 | 可以通过被动备份实现 |
可用性
假设在两个不同的数据中心中都有数据库的副本 (replicas). 副本的要求是, 在一个数据中心中写入数据的同时, 都必须将数据写入另一个数据中心中的副本. 假设客户端只连接到一个数据中心, 那么当数据复制的时候就必须依赖两个数据中心之间的网络链接.
a现在假设网络连接中断 - 这就是网络分区 (network partition) 的意思. 猜猜会发生什么?
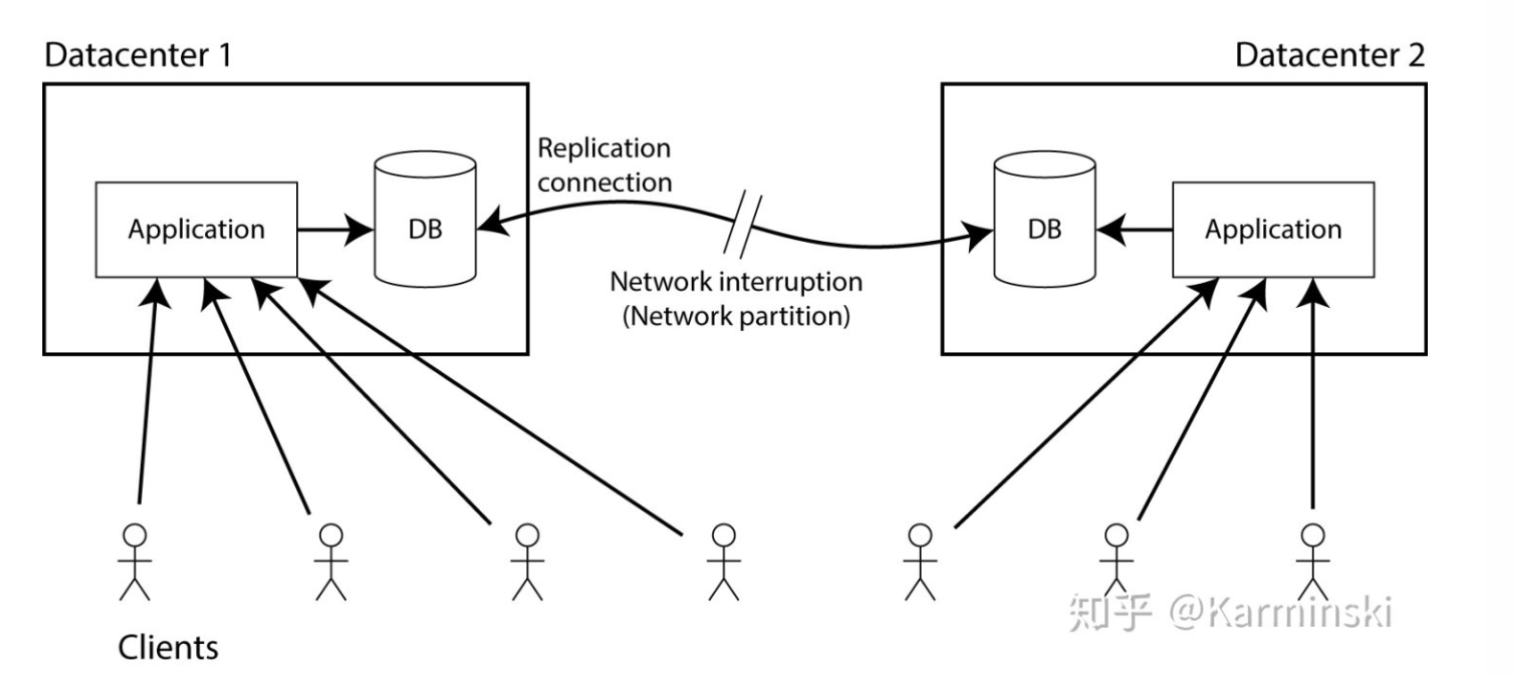
很明显你只能二选一:
1.程序可以继续写入数据库, 所以两个数据中心中数据库都是完全可用的. 但只要数据复制依赖的连接被中断, 在一个数据中心中对数据库的更改将不会同步到另外一个数据中心. 这违反了线性一致性 (linearizability)(在前面的例子中, Alice 可能连接到数据中心1, Bob 连接到了数据中心2).
2.如果不想失去线性一致性 (linearizability), 就必须确保在一个数据中心执行所有读写操作 (可以称作leader), 在另一个数据中心 (由于数据复制依赖的连接中断而无法更新到最新) 在网路分区恢复正常,数据同步完毕之前必须停止接受读写操作. 尽管非 leader 数据库没有失效 (failed), 但他无法处理请求, 因此它不是CAP可用 (CAP-available) 的.
注意, 在选项2中的理论上”不可用” (unavailable) 情况下, 我们仍然在一个数据中心中愉快地处理着请求. 因此如果系统选择了线性一致性 (linearizability, 即它不是cap可用的), 这并不一定意味着网络分区会自动导致应用程序停机. 如果您可以将所有客户端请求转移到 leader 数据中心, 那么客户端实际上根本不会感觉到停机时间.
在实际工程中,可用性并不完全与 CAP 可用性 (CAP-availability) 一致. 应用程序的可用性可能是通过 SLA 来衡量的 (例如, 99.9% 的合法请求必须在1秒内成功返回响应)
| 可用性分类 | 可用水平(%) | 年可容忍停机时间 |
|---|---|---|
| 容错可用性 | 99.9999 | <1 min |
| 极高可用性 | 99.999 | <5 min |
| 具有故障自动恢复能力的可用性 | 99.99 | <53 min |
| 高可用性 | 99.9 | <8.8h |
| 商品可用性 | 99 | <43.8 min |
通常我们描述一个系统的可用性时,我们说淘宝的系统可用性可以达到5个9,意思就是说他的可用水平是99.999%,即全年停机时间不超过 (1-0.99999)*365*24*60 = 5.256 min,这是一个极高的要求。
分区容错性
分区容错性指the system continues to operate despite arbitrary message loss or failure of part of the system,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
服务注册发现组件
了解完CAP,我们来看看服务注册发现组件比较
| Feature | Consul | zookeeper | etcd | euerka |
|---|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱)长连接,keepalive | 连接心跳 | 可配支持 |
| 多数据中心 | 支持 | — | — | — |
| kv存储服务 | 支持 | 支持 | 支持 | — |
| 一致性 | raft | paxos | raft | — |
| cap | cp | cp | cp | ap |
| 使用接口(多语言能力) | 支持http和dns | 客户端 | http/grpc | http(sidecar) |
| watch支持 | 全量/支持long polling | 支持 | 支持 long polling | 支持 long polling/大部分增量 |
| 自身监控 | metrics | — | metrics | metrics |
| 安全 | acl /https | acl | https支持(弱) | — |
| spring | cloud集成 | 已支持 | 已支持 | 已支持 |
ZooKeeper强一致性©带来的问题:
任何时候对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是 Zookeeper 不能保证每次服务请求都是可达的。从 Zookeeper 的实际应用情况来看,在使用 Zookeeper 获取服务列表时,如果此时的 Zookeeper 集群中的 Leader 宕机了,该集群就要进行 Leader 的选举,又或者 Zookeeper 集群中半数以上服务器节点不可用(例如有三个节点,如果节点一检测到节点三挂了 ,节点二也检测到节点三挂了,那这个节点才算是真的挂了),那么将无法处理该请求。所以说,Zookeeper 不能保证服务可用性。
当然,在大多数分布式环境中,尤其是涉及到数据存储的场景,数据一致性应该是首先被保证的,这也是 Zookeeper 设计紧遵CP原则的另一个原因。但是对于服务发现来说,情况就不太一样了,针对同一个服务,即使注册中心的不同节点保存的服务提供者信息不尽相同,也并不会造成灾难性的后果。因为对于服务消费者来说,能消费才是最重要的,消费者虽然拿到可能不正确的服务实例信息后尝试消费一下,也要胜过因为无法获取实例信息而不去消费,导致系统异常要好(淘宝的双十一,京东的幺六八就是紧遵AP的最好参照)。
当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30~120s,而且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署环境下, 因为网络问题使得zk集群失去master节点是大概率事件,虽然服务能最终恢复,但是漫长的选举事件导致注册长期不可用是不能容忍的。
consul,etcd强一致性©带来的是:
服务注册相比Eureka会稍慢一些。因为consul,etcd的raft协议要求必须过半数的节点都写入成功才认为注册成功
Leader挂掉时,重新选举期间整个consul,etcd不可用。保证了强一致性但牺牲了可用性。
euerka保证高可用(A)和最终一致性:
服务注册相对要快,因为不需要等注册信息replicate到其他节点,也不保证注册信息是否replicate成功
当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性。
参考资料
分布式系统一致性 Linearizability vs. Sequential consistency
文章作者 zhengxz
上次更新 2020-02-29